Nulinis balso konvertavimas: „HierSpeech++“ palyginimas su kitais baziniais modeliais

Nuorodų lentelė
Santrauka ir 1 Įvadas
2 Susiję darbai
2.1 Neuroninio kodeko kalbos modeliai ir 2.2 Neautoregresyvūs modeliai
2.3 difuzijos modeliai ir 2.4 nulinis balso klonavimas
3 Hierspeech++ ir 3.1 kalbėjimo atvaizdavimas
3.2 Hierarchinis kalbos sintezatorius
3.3 Tekstas į „Vec“.
3.4 Kalba Itin didelė raiška
3.5 Modelio architektūra
4 Kalbos sintezės užduotys
4.1 Balso konvertavimas ir 4.2 Tekstas į kalbą
4.3 Stiliaus raginimo replikacija
5 Eksperimentas ir rezultatas bei duomenų rinkinys
5.2 Išankstinis apdorojimas ir 5.3 Mokymas
5.4 Vertinimo metrika
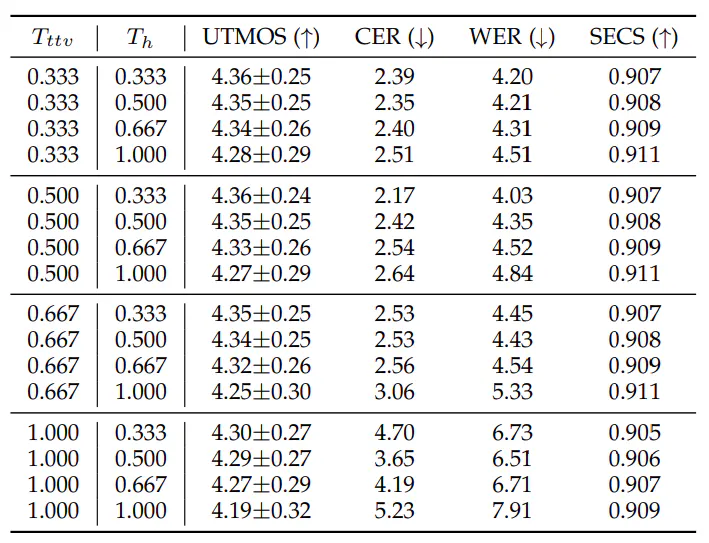
5.5 Abliacijos tyrimas
5.6 Nulinis balso konvertavimas
5.7 Didelės įvairovės, bet labai tikslios kalbos sintezė
5.8 Nulinis tekstas į kalbą
5.9 Nulinis tekstas į kalbą su 1 s raginimu
5.10 Kalba Super didelė raiška
5.11 Papildomi eksperimentai su kitomis bazinėmis linijomis
6 Apribojimas ir greitas pataisymas
7 Išvada, pripažinimas ir nuorodos
5.6 Nulinis balso konvertavimas
Palyginome „HierSpeech++“ balso stiliaus perdavimo našumą su kitais baziniais modeliais: 1) „AutoVC“ (66), kuris yra automatiniu koduotuvu pagrįstas neautoregresyvus VC modelis, naudojant informacijos kliūtį, kad atskirtų turinį ir stilių, 2) „VoiceMixer“ (46), yra GAN pagrįstas lygiagretus VC modelis, kuriame naudojamas panašumu pagrįstos informacijos kliūtis, 3–5) Difuzija pagrįsti modeliai („DiffVC“ (64), „Diff-HierVC“ (11) ir DDDM-VC (10)), 6) „YourTTS“ (7), VITS pagrįsti tiesioginiai VC modeliai, naudojanti fonemų sekas turinio informacijai išgauti, 7) „HierVST“ (45), hierskalbe pagrįstas VC modelis, naudojant hierarchinio stiliaus pritaikymą. Siekiant teisingo palyginimo, apmokėme visus modelius naudodami tą patį duomenų rinkinį (LT460, LibriTTS pogrupiai „train-clean-460“) be „YourTTS“. Mes panaudojome oficialų YourTTS diegimą, kuris buvo apmokytas naudojant papildomą duomenų rinkinį. Taip pat apmokėme modelį naudodami didelio masto duomenų rinkinį, pvz., LT-960, visus „LibriTTS“ mokymo pogrupius) ir papildomus duomenų rinkinius, kad patikrintume duomenų rinkinio didinimo efektyvumą.
Subjektyviam tikslui 5 LENTELĖ rodo, kad mūsų modelis žymiai pagerina konvertuotos kalbos natūralumą ir panašumą nMOS ir sMOS atžvilgiu. Mes nustatėme, kad mūsų modelis su didelio masto duomenų rinkiniu parodė geresnį natūralumą nei kalbos apie pagrindinę tiesą.
Tačiau rezultatai taip pat parodė, kad padidinus duomenų rinkinį nefiltruojant triukšmingų duomenų, garso kokybė, kalbant apie nMOS ir UTMOS, šiek tiek sumažėjo, tačiau panašumas nuolat didėjo pagal duomenų skalę. Be to, WER taip pat parodė geresnį našumą nei kiti modeliai. Be to, panašumo matavimo rezultatai rodo, kad mūsų modeliai veikia geriau pagal EER ir SECS. Be to, rezultatai patvirtino, kad „HierSpeech++“, kuris buvo apmokytas naudojant didelio masto duomenų rinkinį, yra daug stipresnis nulinio vaizdo kalbos sintezatorius.
Į savo demonstracinį puslapį įtrauksime nulinio tarpkalbio balso stiliaus perdavimo rezultatus ir papildomus nulinio balso konvertavimo rezultatus su triukšmingais kalbos raginimais. Primygtinai rekomenduojame klausytis demonstracinių pavyzdžių ir išleisime hierarchinio kalbos sintezatoriaus šaltinio kodą, kad būtų sukurtas stiprus nulinis kalbos sintezatorius. Be to, mes taip pat galime padidinti garso mėginius naudodami SpeechSR nuo 16 kHz iki 48 kHz, o tai gali tiesiog pagerinti suvokimo garso kokybę, kaip aprašyta 5.10 skyriuje.


Autoriai:
(1) Sang-Hoon Lee, Korėjos universiteto Dirbtinio intelekto katedros bendradarbis, IEEE, Seulas 02841, Pietų Korėja;
(2) Ha-Yeong Choi, Korėjos universiteto Dirbtinio intelekto katedros bendradarbis, IEEE, Seulas 02841, Pietų Korėja;
(3) Seung-Bin Kim, Korėjos universiteto Dirbtinio intelekto katedros bendradarbis, IEEE, Seulas 02841, Pietų Korėja;
(4) Seong-Whan Lee, Korėjos universiteto Dirbtinio intelekto katedros bendradarbis, IEEE, Seulas 02841, Pietų Korėja, ir atitinkamas autorius.