Pažangiausi metodai, pagreitinantys dirbtinį intelektą be papildomų išlaidų

Autoriai:
(1) Albertas Gu, Carnegie Mellon universiteto Mašininio mokymosi katedra ir su tokiu pat indėliu;
(2) Tri Dao, Prinstono universiteto Kompiuterių mokslų katedra ir taip pat prisidėjo.
Nuorodų lentelė
Santrauka ir 1 Įvadas
2 valstybiniai kosminiai modeliai
3 atrankiniai būsenos erdvės modeliai ir 3.1 motyvacija: pasirinkimas kaip suspaudimo priemonė
3.2 SSM tobulinimas naudojant atranką
3.3 Veiksmingas atrankinių SSM įgyvendinimas
3.4 Supaprastinta SSM architektūra
3.5 Atrankos mechanizmų savybės
3.6 Papildoma modelio informacija
4 Empirinis įvertinimas ir 4.1 Sintetinės užduotys
4.2 Kalbos modeliavimas
4.3 DNR modeliavimas
4.4 Garso modeliavimas ir generavimas
4.5 Greičio ir atminties standartai
4.6 Modelių abliacijos
5 Diskusija
6 Išvados ir literatūros sąrašas
Diskusija: atrankos mechanizmas
B Susijęs darbas
C Atrankinių SSM mechanika
D Aparatinę įrangą patyręs algoritmas atrankiniams SSM
E Eksperimento informacija ir papildomi rezultatai
3.3 Veiksmingas atrankinių SSM įgyvendinimas
Aparatūrai palankios architektūros, tokios kaip konvoliucijos (Krizhevsky, Sutskever ir Hinton, 2012) ir transformatoriai (Vaswani ir kt., 2017), yra plačiai taikomos. Siekiame, kad atrankiniai SSM būtų veiksmingi ir šiuolaikinėje aparatinėje įrangoje (GPU). Atrankos mechanizmas yra gana natūralus, o ankstesniuose darbuose buvo bandoma įtraukti specialius atrankos atvejus, pavyzdžiui, leisti ∆ keistis laikui bėgant pasikartojančiose SSM (Gu, Dao ir kt., 2020). Tačiau, kaip minėta anksčiau, pagrindinis SSM naudojimo apribojimas yra jų skaičiavimo efektyvumas, todėl S4 ir visos išvestinės priemonės naudojo LTI (neselektyvius) modelius, dažniausiai pasaulinių konvoliucijos pavidalu.
3.3.1 Ankstesnių modelių motyvavimas
Pirmiausia peržiūrime šią motyvaciją ir apžvelgiame savo požiūrį, kaip įveikti ankstesnių metodų apribojimus.
• Aukštu lygiu pasikartojantys modeliai, tokie kaip SSM, visada subalansuoja kompromisą tarp išraiškingumo ir greičio: kaip aptarta 3.1 skyriuje, modeliai su didesniu paslėptos būsenos matmeniu turėtų būti efektyvesni, bet lėtesni. Taigi norime maksimaliai padidinti paslėptos būsenos dimensiją nemokėdami greičio ir atminties išlaidų.
• Atkreipkite dėmesį, kad pasikartojantis režimas yra lankstesnis nei konvoliucijos režimas, nes pastarasis (3) gaunamas išplečiant pirmąjį (2) (Gu, Goel ir Ré 2022; Gu, Johnson, Goel ir kt., 2021). Tačiau tam reikėtų apskaičiuoti ir materializuoti latentinę būseną ℎ su forma (B, L, D, N), daug didesne (N koeficientu, SSM būsenos matmuo) nei formos įvestis x ir išvestis y (B, L, D). Taigi buvo įdiegtas efektyvesnis konvoliucijos režimas, kuris galėtų apeiti būsenos skaičiavimą ir materializuoja tik (B, L, D) konvoliucijos branduolį (3a).
• Ankstesni LTI SSM naudoja dvigubas pasikartojančias konvoliucines formas, kad efektyviosios būsenos matmuo padidėtų Nx koeficientu (≈ 10–100), daug didesniu nei tradiciniai RNN, be efektyvumo baudų.
3.3.2 Atrankinio nuskaitymo apžvalga: aparatinės įrangos būsenos išplėtimas
Atrankos mechanizmas sukurtas siekiant įveikti LTI modelių apribojimus; tuo pačiu metu turime dar kartą peržiūrėti SSM skaičiavimo problemą. Tai sprendžiame trimis klasikiniais metodais: branduolio suliejimu, lygiagrečiu nuskaitymu ir perskaičiavimu. Pateikiame du pagrindinius pastebėjimus:
• Naivus pasikartojantis skaičiavimas naudoja O(BLDN) FLOP, o konvoliucinis skaičiavimas naudoja O(BLD log(L)) FLOP, o pirmasis turi mažesnį pastovų koeficientą. Taigi ilgoms sekoms ir ne per dideliam būsenos matmeniui N pasikartojantis režimas iš tikrųjų gali naudoti mažiau FLOP.
• Du iššūkiai yra nuoseklus pasikartojimo pobūdis ir didelis atminties naudojimas. Norėdami išspręsti pastarąjį, kaip ir konvoliucinį režimą, galime bandyti iš tikrųjų neįgyvendinti visos būsenos ℎ.
Pagrindinė idėja yra panaudoti šiuolaikinių greitintuvų (GPU) savybes, kad būsena būtų materializuota ℎ tik efektyvesniuose atminties hierarchijos lygiuose. Visų pirma, daugumą operacijų (išskyrus matricos dauginimą) riboja atminties pralaidumas (Dao, Fu, Ermon ir kt. 2022; Ivanov ir kt. 2021; Williams, Waterman ir Patterson 2009). Tai apima mūsų nuskaitymo operaciją, o mes naudojame branduolio sujungimą, kad sumažintume atminties IO kiekį, todėl žymiai pagreitėjame, palyginti su standartiniu diegimu.


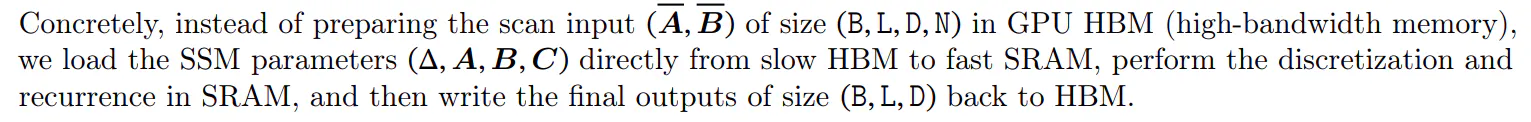
Siekdami išvengti nuoseklaus pasikartojimo, pastebime, kad nepaisant to, kad jis nėra tiesinis, jis vis tiek gali būti lygiagretus su efektyviu lygiagrečiojo nuskaitymo algoritmu (Blelloch 1990; Martin ir Cundy 2018; Smith, Warrington ir Linderman 2023).
Galiausiai, taip pat turime vengti išsaugoti tarpines būsenas, kurios būtinos atgaliniam dauginimuisi. Atsargiai taikome klasikinę perskaičiavimo techniką, kad sumažintume atminties poreikį: tarpinės būsenos neišsaugomos, o perskaičiuojamos atgaline eiga, kai įėjimai įkeliami iš HBM į SRAM. Dėl to lydytam selektyvaus nuskaitymo sluoksniui taikomi tokie patys atminties reikalavimai kaip ir optimizuotam transformatoriui su FlashAttention.
Išsami informacija apie sujungtą branduolį ir perskaičiavimą pateikta D priede. Visas selektyvus SSM sluoksnis ir algoritmas pavaizduoti 1 paveiksle.